ChemBench Update: Is there a new contender for the best model?

Some time has passed after the publication of our ChemBench manuscript on arXiv. Here is an exciting update that puts into perspective the performance of LLM models as these become more efficient and better across benchmarks! Spoiler: there is a new leading model!
New models
In this release, we introduce seven new models. Surprisingly, the highlight of this blog post is the smaller models! When comparing the newly released small LLMs to the older versions of the gargantuan GPT and Claude models, it is clear that we've come a long way when it comes to efficiency! Let's see the updated top-10, where we highlight the new models. Claude-3.5 (Sonnet) is the new top performer, surpassing GPT-4.
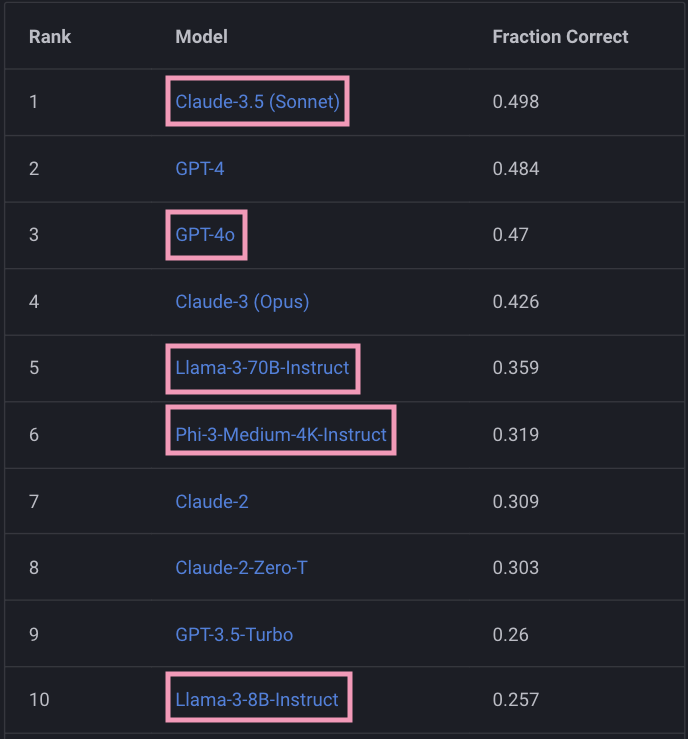
Somewhat puzzling, the newly released GPT-4o does not surpass the performance of its predecessor GPT-4. Moreover, Llama-3 models perform well, considering their size. For example, the Llama-3-8B model matches the performance of GPT-3.5-Turbo, while its larger version with 70B parameters is in the top 5, outperforming Claude-2. The performance of Phi-3, released by Microsoft, is also noteworthy since this is a 14B-parameter model that performs on par with Claude-2.
Improvements
In our April blog, we showcased the performance distribution across various subdomains of chemistry.
At that time, GPT-4 and Claude-3 were the leaders across all categories. This time around, Claude-3.5-Sonnet seems to have taken the solo lead across a vast majority of our designated domains.
One (important) domain it lacks behind GPT-4 is chemical safety.
Surprisingly, four of the new models obtained the maximum score in computational chemistry. Important leaps happened across other domains, such as materials science, analytical chemistry, and organic chemistry. These subcategories have a large number of questions, thus an improvement in the range of 8-30% is certaintly a testament that LLMs are becoming better chemists, gradually increasing the gap between themselves and humans.
What's next?
The team is currently working on a set of challenging questions across domains. We intend with this new set of more advanced questions to determine the real capabilities of large language models. The new set will also be used to generate a new subset of questions for the human baseline. LLMs are not going anywhere so we can try to understand how they can best assist or facilitate the development of new drugs or materials.